인공지능, 블록체인, GPU "인공지능 코드를 테스트해보려면 GPU가 좋아야 해.', '인공지능을 위해 개발된 GPU' '비트코인으로 인한 GPU 대란' 등의 이야기를 심심찮게 들어봤을 것이다. 인공지능와 블록체인에는 왜 GPU로 연산을 하는 것일까?
인공지능과 블록체인은 '쉬운 연산을 엄청나게 많이' 해야 하기 때문이다. 다음 영상을 보면 아주 쉽게 이해될 것이다.
인공지능은 행렬 연산을 엄청나게 많이 해야 하고 블록 체인은 엄청나게 많은 무작위 숫자(난수)를 대입해야 한다. 따라서 좋은 GPU는 연산 시간을 줄이는데 매우 유용하다. GPGPU(General-Purpose computing on Grphics Processing Unit) 원래 GPU의 목적은 CPU의 보조 장치로써 그래픽 처리만 담당했다. 하지만 이후 GPU가 행렬과 벡터 연산에 유용하게 쓰일 수 있다는 점에서 착안해 CPU 대신 GPU로 그래픽 처리 뿐만 아니라 행렬, 벡터 처리까지 가능하도록 만든 것이다. 이렇게 일반적인 목적의 연산(General-Purpose computing)도 처리하는 GPU를 GPGPU 라고 부른다. 그 덕분에 인공지능 학습 속도가 과거에 비해 크게 향상되었다. 필자도 인공지능 공부를 위해 좋은 GPU를 구입해서 파이토치를 구동시켜봤다. GPU가 일을 하고 있나 확인하기 위해 작업관리자로 확인을 해봤다.
사실 GPU를 사용하기 위해서는 GPU를 사용하기 위한 프로그램을 설치해야 한다. 우리가 GPU를 사용하자고 컴퓨터에 알려주지 않았기 때문에 러닝을 돌리면 컴퓨터는 CPU로 연산을 한다. 아래부터는 CUDA라는 프로그램을 설치하는 방법에 대한 글입니다. 현재 설치할 계획이 없으시다면 건너뛰어도 괜찮습니다! 단순 호기심에 설치하다가는 하루를 그냥 날려버릴 수도 있어요!
CUDA GPU로 러닝을 돌리기 위해 사용하는 프로그램이 바로 이 CUDA이다. CUDA는 GPU 제조회사로 유명한 'NVIDIA' 회사용 프로그램이다. (GPU가 NVIDIA 외 다른 회사라면 다른 프로그램을 사용해야 함.) 아래는 설치방법이다. 그 외에도 설치방법은 인터넷에 검색하면 쉽게 찾을 수 있다.
꼭 드라이버 설치 → CUDA 설치 → cuDNN 설치 순서로 진행하자. 설치 전에 설치할 tensorflow 버전, 파이썬 버전, CUDA버전, cuDNN버전이 서로 호환되는지 꼭 확인하고 설치하자!! (정말 매우매우 중요하다. 이거 잘못하면 삽질의 늪에 빠진다.)
GPU 드라이버 호환 확인 GPU 드라이버 설치 후 cmd 창에 nvidia-smi 라고 쳤을 때 Driver Version 값이 높을 수록 좋다. (여기서 (Driver Version에 나오는 숫자는 최대로 설치할 수 있는 버전을 의미한다. 텐서플로우와 호환성을 따져보고 더 낮은 버전을 설치해도 괜찮다.) 예를들어 CUDA11.4.0GA 버전의 툴킷은 Driver Version 값이 471.11(윈도우 기준) 이상이어야 설치해도 문제 없다는 의미이다.
나머지 버전 호환 본인이 설치할 수 있는 CUDA 버전을 확인한 후 그에 맞게 텐서플로우, 파이썬, cuDNN 버전을 맞추면 된다. (가능하면 conda 가상환경에서 사용하는 것을 추천한다.) 설치가 잘 되었다면 nvcc -V 명령어로 잘 설치되었는지 확인할 수 있다. 이 명령어가 실행되지 않으면 잘못 설치한 것이다.
정리 개발환경을 세팅하는 것은 귀찮고 어렵다. 특히 CUDA같은 경우 인공지능 프레임워크와 GPU간의 호환이 전부 맞아 떨어져야 사용이 가능하다. 필자도 다시 지우고 깔기를 엄청 반복했다. 좋은 GPU를 사놓고 CUDA 설정을 못해서 CPU로 인공지능 공부하는 사람이 없어야 한다.
한 시스템에 CPU와 GPU가 병렬로 실행되다 보니 동기화 문제가 발생한다. 예를 들어 그리고자 하는 어떤 기하구조의 위치를 R이라는 자원에 담는다고 하자. 그 기하구조를 위치 p1에 그리려는 목적으로 CPU는 위치 p1을 R에 추가하고, R을 참조하는 그리기 명령 C를 명령 대기열에 추가한다.
명령 대기열에 명령을 추가하는 연산은 CPU의 실행을 차단하지 않으므로, CPU는 계속해서 다음 단계로 넘어간다. 만약 GPU가 그리기 명령 C를 실행하기 전에 CPU가 새 위치 p2를 R에 추가해서 R에 있던 기존 p1을 덮어쓰면, 기하구조는 의도했던 위치에 그려지지 않게 된다.
이런 문제의 해결책은 GPU가 명령 대기열의 명령들 중 특정 지점까지의 모든 명령을 다 처리할 때까지 CPU를 기다리게 하는 것이다. 대기열의 특정 지점까지의 명령을 처리하는 것을 가리켜 명령 대기열을 비운다 또는 방출한다(Flush)라고 말한다.
이때 필요한 것이 바로 울타리(Fence)이다. 울타리(펜스)는 ID3D12Fence 인터페이스로 대표되며, GPU와 CPU의 동기화를 위한 수단으로 쓰인다. 다음은 펜스 객체를 생성하는 메서드이다.
사용 예) m_pd3dDevice->CreateFence(0, D3D12_FENCE_FLAG_NONE, __uuidof(ID3D12Fence), (void**)&m_pd3dFence);
펜스 객체는 UINT64 값 하나를 관리한다. 이 값은 시간상의 특정 펜스 지점을 식별하는 정수이다. 이 값을 0으로 두고, 새 펜스 지점을 만들 때마다 이 값을 1씩 증가시킨다. UINT64의 최대값은 엄청나게 큰 값이기 때문에(약 1.8천경 정도 된다) 아무리 많은 시간동안 게임을 실행하며 이 값을 1씩 증가시킨다고 해도 이 값이 최대 값을 넘어간다는 걱정은 하지 않아도 된다.
다음은 펜스를 이용해서 명령 대기열을 비우는 방법을 보여주는 코드이다. // 현재 펜스 지점까지의 명령들을 표시하도록 펜스 값을 전진 m_nFenceValue++;
// 새 펜스 지점을 설정하는 명령을 명령 대기열에 추가한다. m_pd3dCommandQueue->Signal(m_pd3dFence, m_nFenceValue);
// GPU가 이 펜스 지점까지의 명령들을 완료할 때까지 기다린다. if(m_pd3dFence->GetCompletedValue() < m_nFenceValue) { // GPU가 현재 펜스 지점에 도달했으면 이벤트를 발동시킨다. m_pd3dFence->SetEventOnCompletion(m_nFenceValue, m_hFenceEvent);
// GPU가 현재 펜스 지점에 도달했음을 뜻하는 이벤트를 기다린다. ::WaitForSignalObject(m_hFenceEvent, INFINITE); } 이 코드를 도식화하면 다음과 같다.(생략)
위 숫자 순으로 보면 어떤 순서로 돌아가는지 알 수 있을것이다. GPU는 현재 프레임에서 필요한 명령들을 완료하면 펜스 객체의 값을 하나 증가시키는 명령을 실행하게 된다. CPU는 그 작업을 하기 전까지 대기하는 것이다.
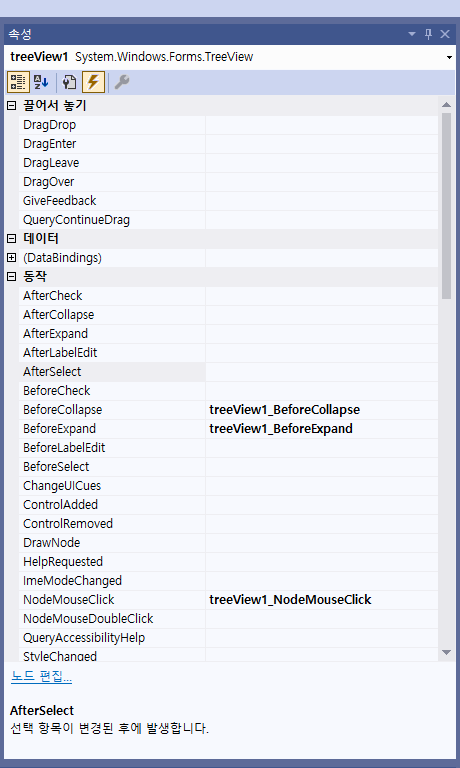
//행 단위 선택 가능 listView1.FullRowSelect = true; } /// <summary> /// 트리를 마우스로 클릭할 때 발생하는 이벤트 /// </summary> /// <param name="sender"></param> /// <param name="e"></param> private void treeView1_NodeMouseClick(object sender, TreeNodeMouseClickEventArgs e) { try { //기존의 파일 목록 제거 listView1.Items.Clear(); DirectoryInfo dir = new DirectoryInfo(e.Node.FullPath);
int DirectCount = 0; //하부 데렉토르 보여주기 foreach (DirectoryInfo dirItem in dir.GetDirectories()) { //하부 디렉토리가 존재할 경우 ListView에 추가 //ListViewItem 객체를 생성 ListViewItem lsvitem = new ListViewItem();
//생성된 ListViewItem 객체에 똑같은 이미지를 할당 lsvitem.ImageIndex = 2; lsvitem.Text = dirItem.Name;
//아이템을 ListView(listView1)에 추가 listView1.Items.Add(lsvitem); listView1.Items[DirectCount].SubItems.Add("");
C# 언어에서는 메모리를 직접 할당하고 해제하는 것이 아니라, .NET 프레임워크가 메모리를 자동으로 관리합니다. .NET 프레임워크는 메모리를 할당하고, 필요한 경우 메모리를 자동으로 해제합니다.
C# 언어는 가비지 컬렉션(Garbage Collection)이라는 기능을 제공하여 사용되지 않는 메모리를 자동으로 탐지하고 제거합니다. 가비지 컬렉터는 메모리를 자동으로 관리하여 메모리 누수를 방지하고, 프로그램의 안정성을 높입니다.
C# 언어는 메모리를 자동으로 관리하기 때문에, 메모리를 직접 관리하는 것보다 쉽고 편리합니다. 하지만, 메모리를 자동으로 관리하는 것은 메모리 관리에 대한 이해와 지식이 필요하지 않다는 것은 아닙니다. C# 언어에서도 메모리를 효율적으로 사용하고, 메모리 누수를 방지하기 위해서는 메모리 관리에 대한 이해와 지식이 필요합니다.
Java 언어에서는 메모리를 직접 할당하고 해제하는 것이 아니라, Java 가상 머신(JVM)이 메모리를 자동으로 관리합니다. JVM은 메모리를 할당하고, 필요한 경우 메모리를 자동으로 해제합니다.
Java 언어는 가비지 컬렉션(Garbage Collection)이라는 기능을 제공하여, 사용되지 않는 메모리를 자동으로 탐지하고 제거합니다. 가비지 컬렉터는 메모리를 자동으로 관리하여 메모리 누수를 방지하고, 프로그램의 안정성을 높입니다.
Java 언어는 메모리를 자동으로 관리하기 때문에, 메모리를 직접 관리하는 것보다 쉽고 편리합니다. 하지만, 메모리를 자동으로 관리하는 것은 메모리 관리에 대한 이해와 지식이 필요하지 않다는 것은 아닙니다. Java 언어에서도 메모리를 효율적으로 사용하고, 메모리 누수를 방지하기 위해서는 메모리 관리에 대한 이해와 지식이 필요합니다.