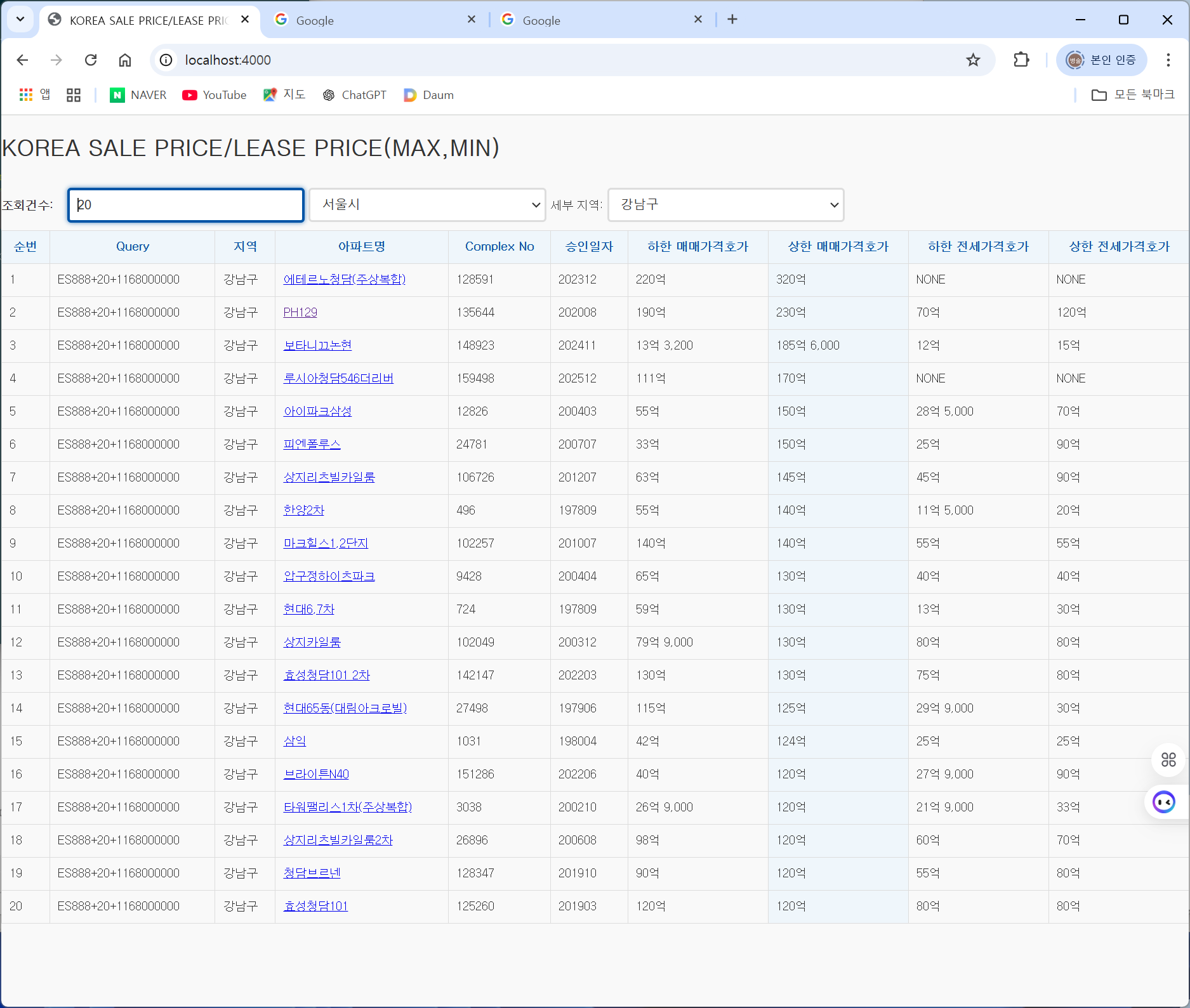
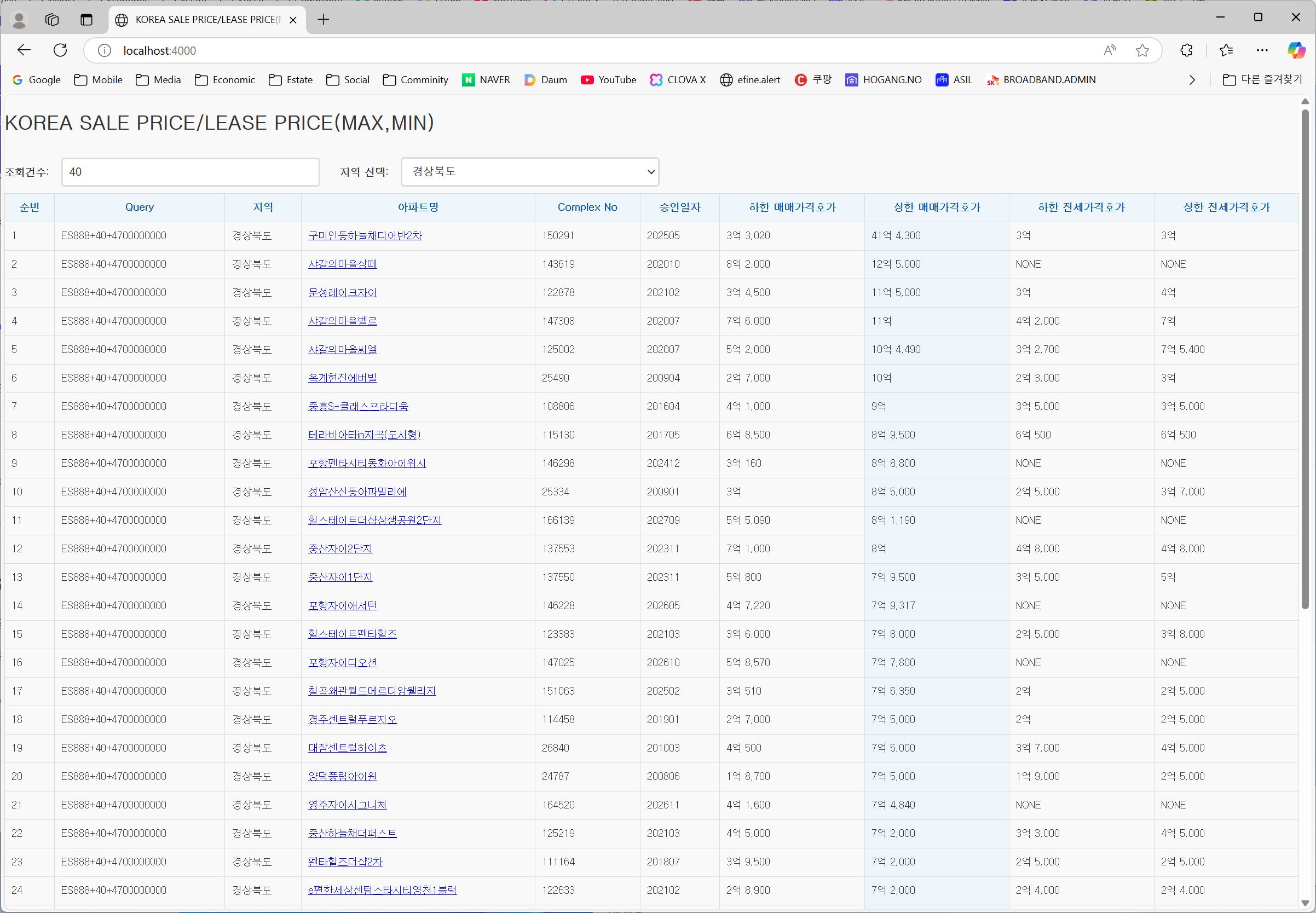
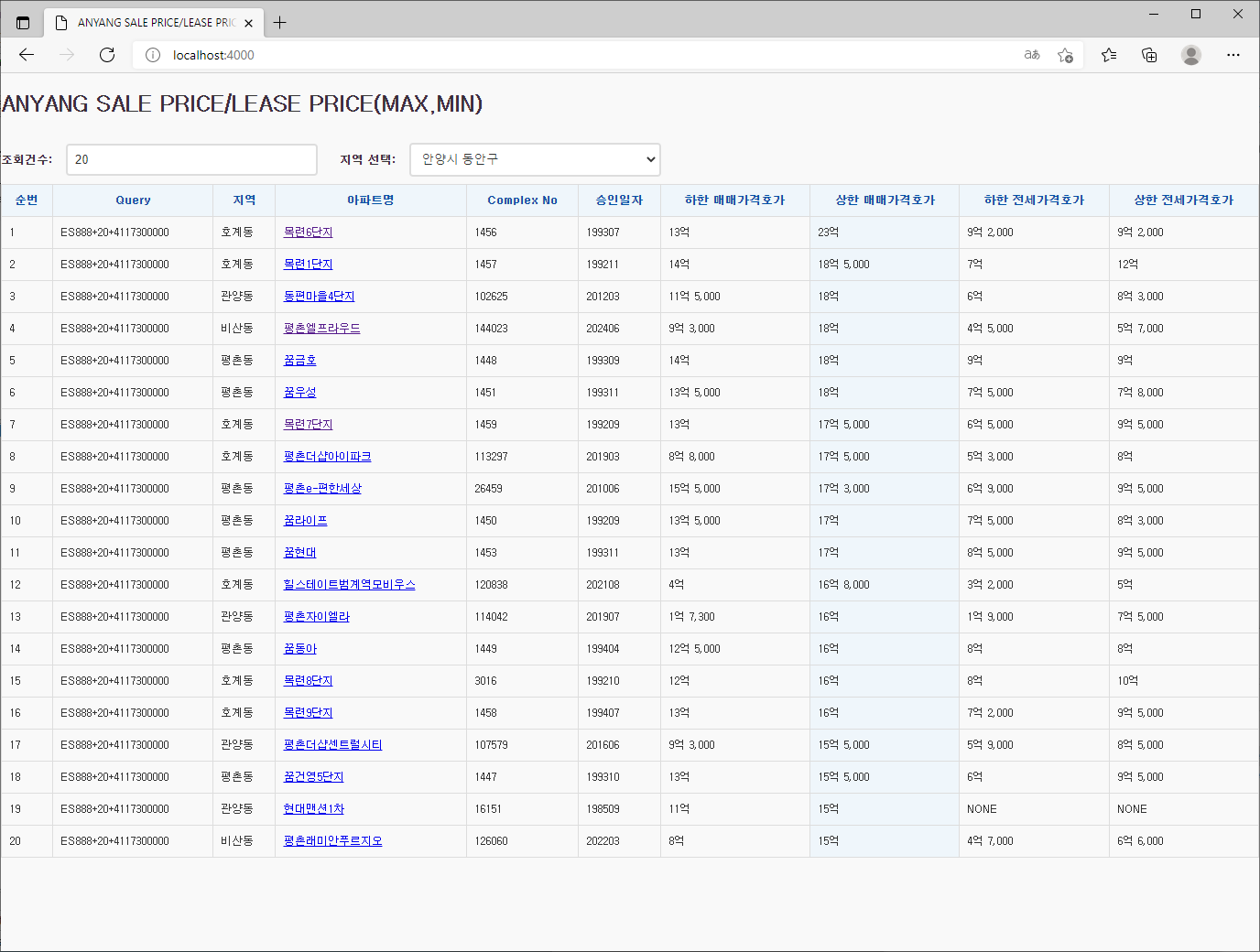
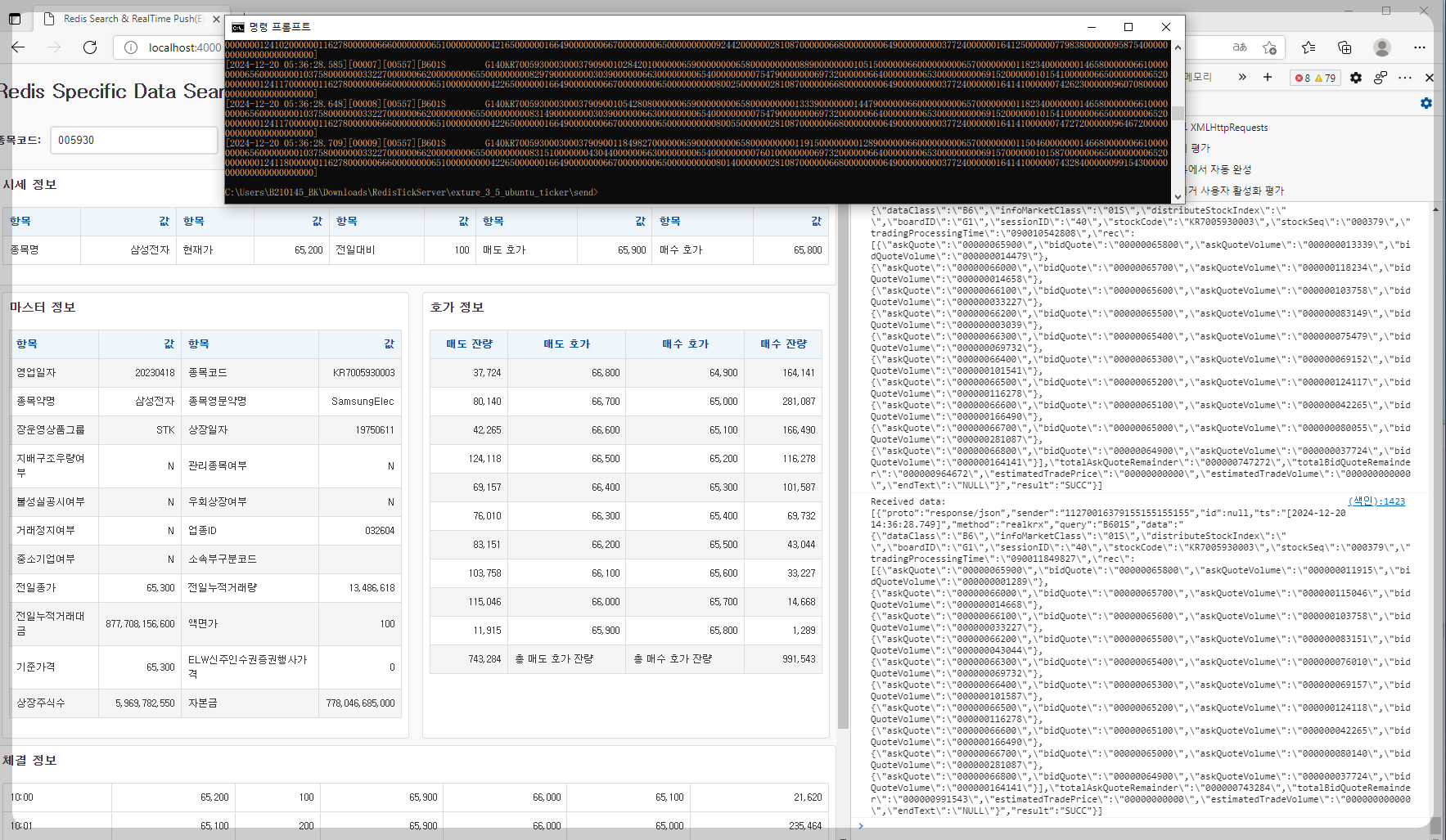
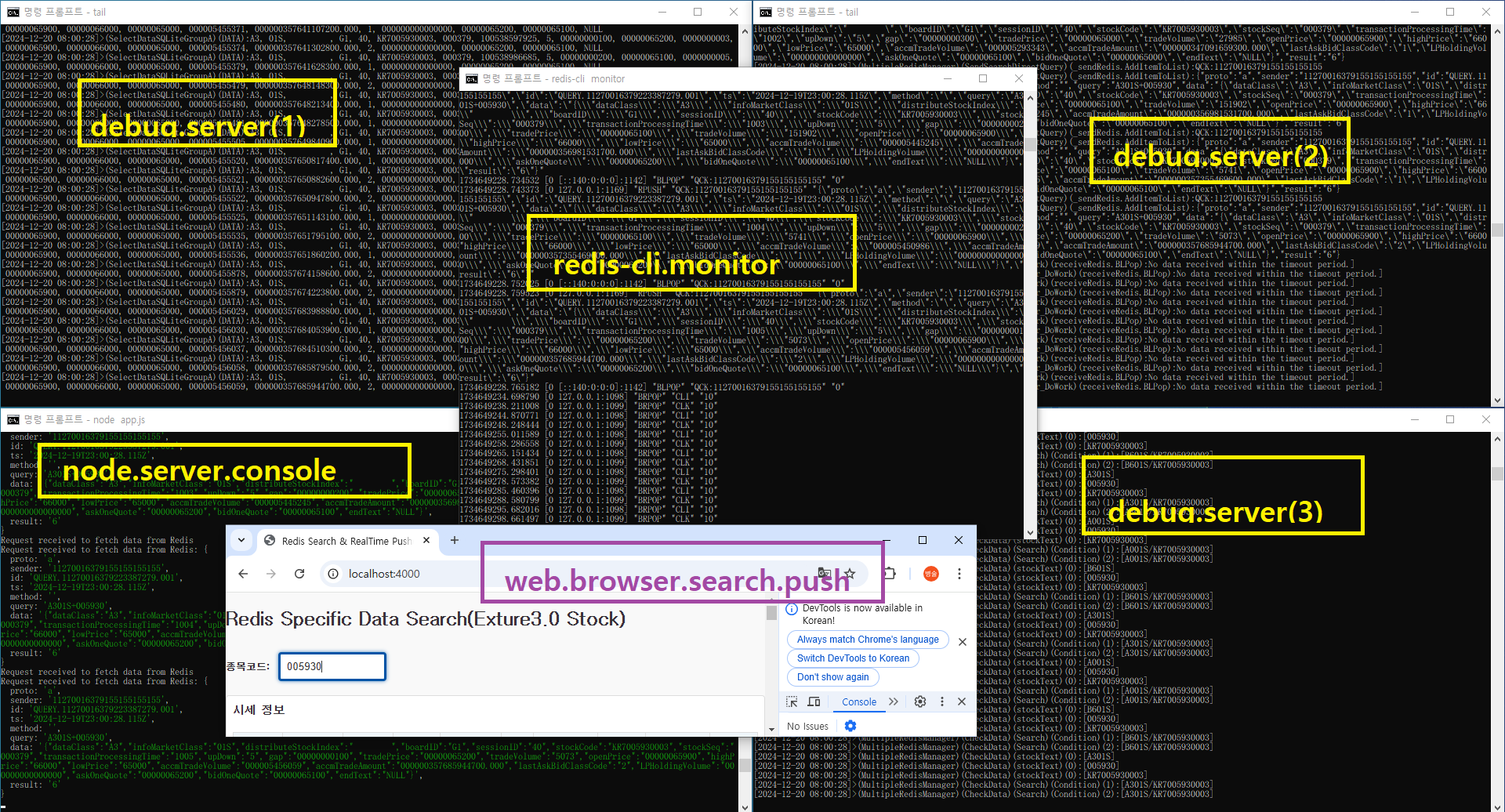
Redis에서 시스템에서 사용할 수 있는 최대 메모리를 확인하려면, INFO MEMORY 명령어와 함께 maxmemory 설정을 통해 Redis가 할당할 수 있는 최대 메모리 용량을 확인할 수 있습니다.
1. maxmemory 설정 확인
Redis는 메모리 사용에 제한을 둘 수 있는 설정(maxmemory)이 있으며, 이 값을 확인하려면 CONFIG GET 명령어를 사용합니다.
redis-cli CONFIG GET maxmemory
이 명령어는 Redis 서버가 할당할 수 있는 최대 메모리의 값을 반환합니다. 예를 들어, maxmemory가 설정되지 않은 경우 0이 반환되며, 이는 제한 없이 Redis가 사용할 수 있음을 의미합니다.
예시:
redis-cli CONFIG GET maxmemory
출력 예시:
1) "maxmemory" 2) "1073741824"
위 예시에서는 maxmemory가 1073741824 (1GB)로 설정되어 있음을 나타냅니다. 만약 maxmemory가 0이라면 Redis는 메모리에 제한 없이 사용할 수 있습니다.
2. 전체 시스템 메모리 확인
Redis가 할당할 수 있는 최대 메모리는 운영 체제에서 Redis 프로세스에 할당된 메모리와도 관련이 있습니다. INFO MEMORY 명령어로 전체 시스템의 메모리 크기를 확인할 수 있습니다.
redis-cli INFO MEMORY
출력 예시:
# Memory used_memory:12345678 used_memory_human:11.77M used_memory_rss:98765432 used_memory_peak:23456789 mem_fragmentation_ratio:1.78 total_system_memory:8388608000
위 예시에서 **total_system_memory**는 시스템 전체 메모리 용량을 나타내며, 이는 Redis가 실행되고 있는 서버의 전체 RAM 용량입니다.
요약:
- Redis가 사용할 수 있는 최대 메모리는 CONFIG GET maxmemory 명령어로 확인할 수 있습니다.
- 전체 시스템 메모리는 INFO MEMORY 명령어에서 total_system_memory 항목으로 확인할 수 있습니다.
- maxmemory 설정이 0인 경우 Redis는 시스템 전체 메모리의 사용에 제한이 없습니다.
My Case)
| C:\Users\xterm>redis-cli CONFIG GET maxmemory 1) "maxmemory" 2) "1572864000" C:\Users\xterm>redis-cli INFO MEMORY # Memory used_memory:9875616 used_memory_human:9.42M used_memory_rss:9816928 used_memory_peak:9875616 used_memory_peak_human:9.42M used_memory_lua:36864 mem_fragmentation_ratio:0.99 mem_allocator:jemalloc-3.6.0 |
C:\Users\xterm>redis-cli CONFIG GET maxmemory
1) "maxmemory"
2) "1572864000"
1) "maxmemory"
2) "1572864000"
1 메가바이트(MB)는 1,048,576 바이트입니다. 따라서:
1572864000 bytes÷1048576=1500 MB1572864000 \, \text{bytes} \div 1048576 = 1500 \, \text{MB}따라서, 1572864000 바이트는 **1500 메가바이트(MB)**입니다.
'REDIS' 카테고리의 다른 글
| REDIS 데이터 영구화를 위한 옵션(코드에서 사용자가 지정한 파일명과 별도임) (0) | 2025.01.09 |
|---|---|
| Caution) 중요한 데이타의 경우에 Redis 서버 설정 및 백업/복원 스크립트 작성해서, ReBoot시에 대비한다. (0) | 2025.01.09 |
| Redis에 할당된 전체 메모리 용량을 확인 (0) | 2025.01.04 |
| Redis에서 각 키에 해당하는 데이터 유형을 확인/리스트의 크기 (0) | 2025.01.04 |
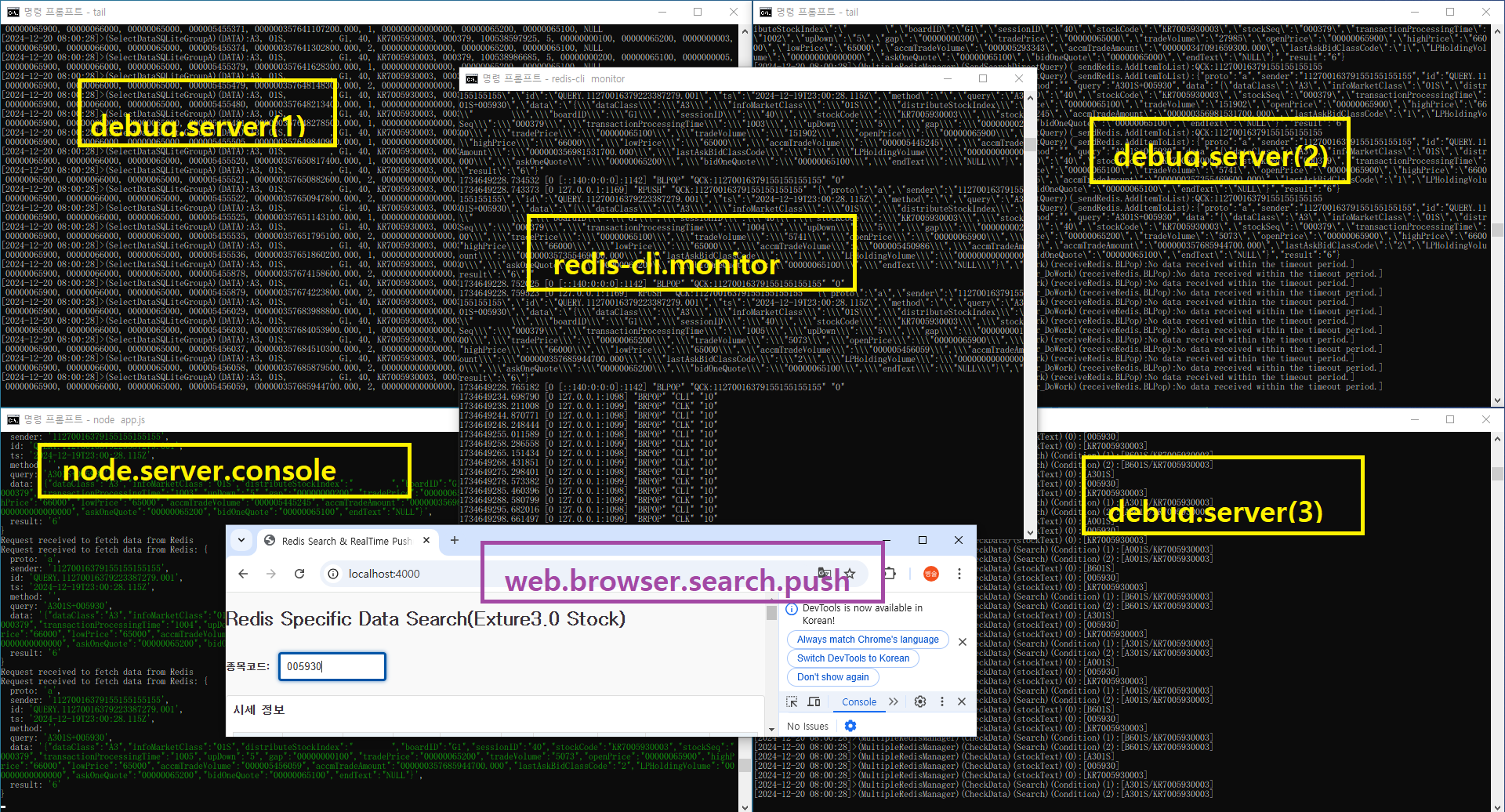
| [redis-cli monitor]-제공된 로그.분석 (1) | 2024.12.20 |